Intelligens dokumentumfeldolgozás
MI AZ INTELLIGENS DOKUMENTUMFELDOLGOZÁS?
Az intelligens dokumentumfeldolgozás (IDP) egy fejlett AI-technológia az automatizált kötegelt feldolgozáshoz és az adatok nagy mennyiségű dokumentumból történő kinyeréséhez. Az IDP kifinomult számítógépes látvány algoritmusokat és mesterséges intelligenciát alkalmaz a különböző típusú dokumentumokból származó szükséges adatok automatikus észlelésére és rögzítésére. A feldolgozott dokumentumok közé tartoznak a számlák és a beszerzési megrendelések, szerződések, nyugták, többféle űrlap, felmérések, személyazonosító okmányok, biztosítási igények és egyebek. Az intelligens dokumentumfeldolgozás több évnyi kézi munkát takarított meg a bankok, a pénzügyi szolgáltatások, a biztosítás, az egészségügy, a kormányzat, a logisztika és más iparágak számára.
Az IDP kiküszöböli a kézi dokumentumrendezés szükségességét, és jelentősen csökkenti a kézi adatbevitellel kapcsolatos hibák számát. Bár egyetlen IDP-rendszer sem tudja garantálni az adatbevitel 100% -os pontosságát, óriási segítséget nyújt azáltal, hogy automatikusan rögzíti az adatok 80-95% -át, keresztellenőrzi az adatokat más források tartalmával, és kiemeli az emberi jóváhagyást igénylő területeket. Most az összes adatmező manuális beírása helyett az emberi operátoroknak csak az adatok körülbelül 10-20% -át kell ellenőrizniük, és néhány lehetséges hibát ki kell javítaniuk. Az IDP gyorsabbá, pontosabbá és költséghatékonyabbá teszi a dokumentumok feldolgozását – ami nagyobb termelékenységet és kevesebb hibát eredményez a kritikus üzleti folyamatokban.
MIT CSINÁL AZ IDP TECHNOLÓGIA?
Az IDP technológia lehetővé teszi a különböző forrásokból gyűjtött nagy dokumentumkötegek teljes körű feldolgozását, beleértve a digitális PDF-eket, a beolvasott dokumentumokat, a mobil fényképeket, a faxokat és más formátumokat. Ezek lehet, hogy csomagokban érkeznek, különböző dokumentumokat – például jelzáloghiteleket – kombinálva, mely esetén minden dokumentumot külön kell választani, azonosítani és egyedileg feldolgozni, majd az ezekből a dokumentumokból származó adatokat össze lehet vetni a pontosság biztosítása érdekében.
Az IDP-megoldások által végrehajtott tipikus feldolgozási lépések a következők:
- Dokumentumbevitel
- Dokumentumok osztályozása és szétválasztása
- Adatok kinyerése
- Adatellenőrzés
- Adatok és exportálás
Dokumentumbevitel
Az IDP technológia lehetővé teszi a különböző forrásokból gyűjtött nagy dokumentumkötegek teljes körű feldolgozását, beleértve a digitális PDF-eket, a beolvasott dokumentumokat, a mobil fényképeket, a faxokat és más formátumokat. Ezek lehet, hogy csomagokban érkeznek, különböző dokumentumokat – például jelzáloghiteleket – kombinálva, mely esetén minden dokumentumot külön kell választani, azonosítani és egyedileg feldolgozni, majd az ezekből a dokumentumokból származó adatokat össze lehet vetni a pontosság biztosítása érdekében.
Az IDP-megoldások által végrehajtott tipikus feldolgozási lépések a következők:
- Dokumentumbevitel
- Dokumentumok osztályozása és szétválasztása
- Adatok kinyerése
- Adatellenőrzés
- Adatok és exportálás

A dokumentumok különböző forrásokból és különböző formátumokban érkezhetnek egy szervezetbe. Ennek a lépésnek a célja az összes hatékonyan feldolgozandó dokumentum összegyűjtése.
A legtöbb innovatív szervezet e-mailben kapja meg a dokumentumokat mellékletként, vagy letölthető fájlként webportálokról (pl. DocuSign segítségével), így a dokumentumok általában jó minőségűek, digitálisan generáltak és viszonylag könnyen feldolgozhatók.
Sok hagyományos vállalkozás és kormányzati szerv azonban még mindig papíralapú dokumentumokat kap postai úton, melyek beolvasást igényelnek, ami további problémákat okozhat, például ferde oldalakat, rossz minőségű beolvasásokat és egymást átfedő színeket, jelentősen növelve a feldolgozás összetettségét.
Az egészségügyi szervezetek még mindig széles körben használnak faxokat, amelyek még bonyolultabbá teszik a helyzetet, hiszen az így küldött képek nagyon rossz minőségűek, és rendkívül nehéz feldolgozni őket. Egyes vállalatok mobil fényképeket gyűjtenek a dokumentumokról, beleértve a csekkeket, személyazonosító okmányokat, nyugtákat, hitel- és biztosítási kártyákat, jegyeket és egyéb kisméretű dokumentumokat. Ezeket is nehéz feldolgozni, mivel az emberek gyakran sötét, homályos, árnyékos képeket készítenek összetett, nehezen eltávolítható háttereken.
Az intelligens dokumentum-feldolgozási megoldások képesek feldolgozni ezeket a dokumentumokat, azonban gyakran speciális összekötőket vagy RPA-robotokat használnak különböző forrásokból érkező dokumentumok gyűjtésére, mint például e-mail mellékletekből, mappák vizsgálatából, FTP-kiszolgálókról és más helyekről.
A dokumentumok osztályozása és elkülönítése

A szkennerekből vagy faxokból érkező több dokumentumot gyakran nagy csomagokba egyesítik. Gondoljon a 200-300 oldalas jelzáloghitel-kérelmekre, amelyeket aláír. A feldolgozáshoz ezeket a dokumentumokat el kell különíteni és azonosítani kell. Hasonlóképpen, egy számlával ellátott e-mail más mellékleteket is tartalmazhat, így a rendszernek képesnek kell lennie a dokumentumok automatikus rendezésére és csak a feldolgozandó dokumentumok kiválasztására.
A dokumentumbesorolás segít ellenőrizni a csomag teljességét és azonosítani a hiányzó dokumentumokat az összes adat kinyerése előtt.
Technológiai szempontból a dokumentumok besorolása a kezdeti lépés, amely lehetővé teszi a megfelelő ML modell kiválasztását és alkalmazását az adatok kinyeréséhez.
Adatok kinyerése

Az adatkinyerés célja a strukturálatlan adatok olvasása és átalakítása a dokumentumokból strukturált formába, amely felhasználható az automatikus feldolgozáshoz.
A dokumentumokból történő adatkinyerés általában az optikai karakterfelismerő (OCR) technológia használatával kezdődik, hogy felismerje és kinyerje a szöveget a beolvasott képekből vagy akár néhány elektronikus dokumentumból. A kinyert szöveget ezután természetes nyelvi feldolgozási (NLP) technológiával vagy gépi tanulási algoritmusokkal dolgozzák fel adott adatmezők, például nevek, címek és dátumok azonosítására és rögzítésére.
A kinyert adatok strukturált formátumba vannak rendezve, amely könnyen elérhető és felhasználható más alkalmazások vagy robotok számára az automatizált feldolgozáshoz.
A dokumentumokból történő adatkinyerés összetett folyamat, amely soha nem garantálja a kinyert adatok 100%-os pontosságát. A pontosság az eredeti dokumentum minőségétől, az OCR és NLP algoritmusok képességeitől, valamint a kinyerendő adatelemek összetettségétől függ.
Adatellenőrzés

Mivel a kinyert adatok soha nem 100% -ban pontosak, mindig ellenőrzést igényelnek.
Az adatellenőrzés elengedhetetlen az intelligens dokumentumfeldolgozásban, mivel segít biztosítani a kinyert adatok megbízhatóságát. Az adatok pontossága kétféleképpen ellenőrizhető:
- Automatikus ellenőrzés
- Emberi ellenőrzés
Az automatikus adatellenőrzés általában magában foglalja a kinyert adatok összehasonlítását előre meghatározott szabályokkal, vagy a meglévő adatbázisok és más megbízható adatforrások keresztellenőrzését annak megállapítására, hogy az adatok helyesek és teljesek-e.
Egy adat-ellenőrzési szabály meghatározhatja például, hogy a dátumnak meghatározott formátumúnak kell lennie vagy, hogy a névnek bizonyos számú szóból kell állnia. Ha a kiemelt adatok nem felelnek meg ezeknek a feltételeknek, a rendszer automatikusan javíthatja vagy megjelölheti őket emberi ellenőrzésre.
Az emberi ellenőrzéshez az IDP-megoldások általában osztott képernyős grafikus felhasználói felületet biztosítanak, amely az egyik oldalon mutatja a forrásadatok helyét az eredeti dokumentumban, a másik oldalon pedig a kinyert adatmezőket. Az ML adatkinyeréshez használt modellek általában kiszámítják az adatfelismerés megbízhatósági szintjét, és kiemelik az alacsony megbízhatóságú adatokat, amelyek emberi felülvizsgálatot igényelnek. Ez időt takarít meg az emberi operátorok számára, hogy a bizonytalan adatmezőkre összpontosíthassanak.
Adatok exportálása
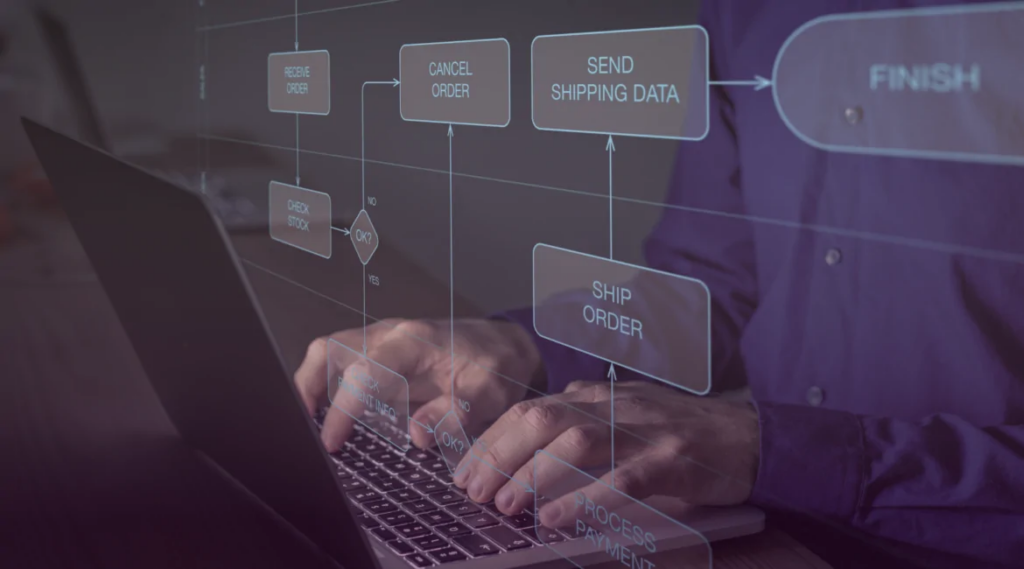
Miután az adatokat ellenőrizték, és pontosnak és teljesnek ítélték, exportálni kell őket az azokat használó háttéralkalmazásokba. Az adatok exportálásának különböző módjai vannak a háttéralkalmazások konkrét követelményeitől és képességeitől függően.
Az adatok exportálhatók például CSV- vagy Excel-fájlként, amely könnyen importálható számos különböző típusú alkalmazásba. Másik lehetőségként az adatok exportálhatók egy adott adatcsere-formátummal, például XML-lel vagy JSON-nal, amelyet az alkalmazások közötti adatátvitelre terveztek.
Bizonyos esetekben az érvényesített adatok közvetlenül a háttéralkalmazásnak küldhetők egy alkalmazásprogramozási felület (API) használatával, amely lehetővé teszi a két rendszer valós idejű kommunikációját egymással.
MI A KÜLÖNBSÉG AZ IDP ÉS AZ OCR KÖZÖTT?
Az OCR vagy optikai karakterfelismerés egy olyan technológia, amelyet a karakterek felismerésére és a beolvasott képek szövegének olvasására használnak. Mintafelismerő algoritmusokat használ a kép egyes karaktereinek azonosítására és azok géppel olvasható szöveggé alakítására. A karakterek kombinációja olyan szavakat alkot, amelyeket beágyazott szótárak ellenőriznek. Az OCR az intelligens dokumentumfeldolgozás (IDP) kritikus eleme, amely alapot biztosít az adatok dokumentumokból történő kinyeréséhez.
Az intelligens dokumentumfeldolgozás (IDP) ezt a következő szintre emeli. Túlmutat az OCR-en, és más technológiákat, például a természetes nyelvi feldolgozást (NLP) és a gépi tanulást használja a kinyerendő adatok pontos azonosításához. Ezek lehetnek űrlapok vagy számlák strukturált vagy félig strukturált adatmezői, esetleg lehetnek szerződések és jogi dokumentumok strukturálatlan szövegben leírt konkrét záradékai.
Az internetszolgáltató további képességeket is biztosít, például 3. féltől származó adatforrások csatlakoztatását az automatikus adatellenőrzéshez, felhasználói felületet az emberi ellenőrzéshez, valamint összekötőket a dokumentumok importálásához és exportálásához. Egyes speciális IDP-megoldások lehetővé teszik ML modellek egyéni betanítását adott dokumentumtípusokhoz vagy tartományokhoz. Néhányuk felhasználhatja az emberi ellenőrzés eredményeit a gépi tanulási modell továbbfejlesztéséhez.
Összefoglalva, az OCR a szövegek képekből történő olvasásának alapvető technológiája, míg az IDP a dokumentumokból származó strukturálatlan tartalmat strukturált adatokká alakítja, amelyek aztán az automatizált folyamatokban használhatók fel.
HOGYAN MŰKÖDIK AZ IDP A VÁLLALKOZÁSOK SZÁMÁRA?
Az adatok kulcsfontosságú eszközök, és minden szervezet kétféle adattal foglalkozik:
- Számolótáblába vagy adatbázistáblába helyezhető strukturált adatok
- strukturálatlan adatok, amelyek dokumentumokat, képeket, videókat, hangot stb. tartalmaznak.
Az adatok 80-90% -a strukturálatlan, ami azt jelenti, hogy nehezen hozzáférhetők és nem használhatók automatikus feldolgozásra, hacsak nem alakítják át strukturált formába.
A dokumentumok strukturálatlan formában tartalmazzák a legfontosabb üzleti adatokat. Bármely szervezet sikeréhez elengedhetetlen, hogy hatékonyan tudja feldolgozni a dokumentumokat.
Ez az oka annak, hogy az IDP-megoldások olyan értékesek minden vállalkozás számára.
AZ INTELLIGENS DOKUMENTUMFELDOLGOZÁS ELŐNYEI
Az IDP számos előnyt kínál minden szervezet számára:
- Akár 90% idő és erőforrás megtakarítás a kézi dokumentumfeldolgozáson
- A hibák számának csökkenése, mivel az emberi operátorok a gépelés helyett az adatok ellenőrzésére összpontosítanak
- Nagyobb ügyfél-elégedettség elérése gyorsabb és magasabb színvonalú szolgáltatás nyújtásával, beleértve a megrendelések feldolgozását, a számlák kifizetését, a biztosítási követelések feldolgozását és az egyéb dokumentumokkal kapcsolatos folyamatok felgyorsítását
HOGYAN MŰKÖDIK AZ IDP AZ RPA-VAL?
Az intelligens dokumentumfeldolgozás (IDP) és a robotikus folyamatautomatizálás (RPA) gyakran kéz a kézben járnak, automatizálva a dokumentumspecifikus folyamatokat. Míg az IDP kinyeri az adatokat a dokumentumokból, az RPA lehetővé teszi a különböző forrásokból származó dokumentumok bevitelét és az adatok exportálását lefelé irányuló alkalmazásokba.
Az RPA technológia egyedülálló rugalmassága lehetővé teszi, hogy gyakorlatilag bármilyen dokumentumforráshoz csatlakozzon: gyűjtsön e-mail mellékleteket, ellenőrizze a szkenner mappáit, hozzáférjen a faxkiszolgálókhoz, FTP-hez és webtárolókhoz.
Az RPA-robotok bármilyen formátumban felvehetik az exportált adatokat, és API-n vagy felhasználói felületen keresztül feltölthetik azokat a háttérrendszerbe.
Az RPA és az IDP technológiák együttesen lehetővé teszik a teljes körű dokumentumfeldolgozást.
MELYEK AZ IDP HASZNÁLATI LEHETŐSÉGEI?
Az intelligens dokumentumfeldolgozási használati esetek általában adott dokumentumtípusok feldolgozásához kapcsolódnak. Vannak gyakori horizontális és iparág-specifikus vertikális felhasználási esetek.
A horizontális használati lehetőségek a következők:
- Tranzakciós dokumentumok: számlák és beszerzési rendelések
- Jogi dokumentumok: megállapodások és szerződések
- HR dokumentumok: önéletrajzok, igazolványok és különféle űrlapok
- Adó- és költségbizonylatok és átvételi elismervények
A vertikális felhasználási lehetőségek iparáganként eltérőek, de a leggyakoribbak a következők:
- Jelzálog- és hitelfeldolgozás a banki szolgáltatásokban
- Kárrendezés a biztosításban
- Űrlapok, népszámlálási felmérések, szavazólapok a kormányban
- Szállítási dokumentumok a szállításban, stb.
A dokumentum típusától és a forrástól függően az IDP-megoldás különböző képalkotási technológiát és ML modelleket használhat az adott használati esetek támogatásához.
HOGYAN VÁLASSZUK KI AZ IDP SZOFTVERT?
Az intelligens dokumentumfeldolgozási technológia különböző formátumokba csomagolható.
- Előre betanított ML modellek adott dokumentumtípusokhoz, amelyek felhőszolgáltatásként érhetők el API-n (például Google és Microsoft Document AI) vagy alapszintű OCR-szolgáltatásokon (például Amazon Textract) keresztül. Ezek a szolgáltatások olyan fejlesztők számára készültek, akik egy alkalmazásba vagy RPA-robotba csomagolhatják őket, így az üzleti felhasználók dolgozhatnak velük.
- Üzleti, felhasználóbarát platformok, amelyek kényelmes felhasználói felületet biztosítanak a dokumentumok feltöltéséhez, az adatkinyerési eredmények ellenőrzéséhez. Egyes speciális platformok lehetővé teszik különböző AI-modellek kiválasztását vagy egyéni modellek betanítását adott dokumentumokhoz.
Egyes szállítók előre betanított modellekkel ellátott csomagolt megoldásokat kínálnak, míg mások nagymértékben testreszabható platformokat kínálnak, amelyek további szolgáltatásokat igényelnek a modellek adott használati esetekhez való hangolásához.
Általában a szállítók több tapasztalattal rendelkeznek bizonyos felhasználási esetekkel vagy iparágakkal való együttműködésben; ezért elengedhetetlen, hogy referenciákat és sikertörténeteket kérjen az érdeklődési köréből.
Áttekintheti az IDP-szállítók listáját és szakértelmét az RPA Master catalog-ben.
Forrás: https://rpamaster.com/intelligent-document-processing/
Kérj tanácsot digitális folyamatautomatizáláshoz
Megoldások területenként
Menü